





Unisound Unveils U1-OCR: The First Industrial-Grade Document Intelligence Model, Ushering in OCR 3.0 Era
BEIJING, Feb. 26, 2026 /PRNewswire/ -- Unisound has officially launched its Unisound U1-OCR, the world's first industrial-grade foundation model for document intelligence, a groundbreaking release that ushers in the OCR 3.0 era and sets a new industry standard with five core strengths: SOTA performance, verifiable results, out-of-the-box functionality, efficient deployment, and robust adaptability.
Document intelligence leverages AI to automatically read, understand, classify digitized documents and extract key information. OCR 1.0 only enabled basic text recognition, while OCR 2.0 added preliminary layout understanding capabilities. U1-OCR takes a quantum leap to OCR 3.0, moving far beyond layout recognition to deliver deep semantic insight, automatic document classification and business-level information extraction—marking a transformative shift from "character perception" to "document cognition".
As a SOTA-level document intelligence model, U1-OCR resolves the longstanding bottleneck of traditional models that "recognize text but fail to grasp layout", enabling it to interpret complex documents like human experts. It pioneers a "semantic-driven + dynamic focus" strategy, first mapping a document's hierarchical structure of headings and structural metadata before extracting content on demand, and builds a semantic map to identify the relationship between titles, charts and text—even in disorganized layouts. Its enhanced spatial alignment module leverages positional data to accurately restore document structure for dense tables and mixed text-image content, effectively mitigating spatial recognition errors. Equipped with Multi-Token Prediction technology and full-task reinforcement learning, it boosts reasoning efficiency by over 80%, ensuring logical coherence for long documents.
Trained with multi-task collaborative reinforcement learning and optimized for both semantics and coordinates, U1-OCR suppresses spatial hallucinations for reliable outputs, and achieves SOTA results across major authoritative benchmarks: scoring 95.1 in OmniDocBench V1.5, outperforming leading models like GLM-OCR and Gemini-3-Pro; hitting an F1 score of 90.8 in D4LA and 95.9 in DocLayNet, excelling in table recognition and cross-page association; and outperforming models such as Gemini-2.5-Flash and Qwen-2.5-VL in internal business tests, with standout performance in medical document processing such as admission and discharge records.

Figure:Comparison of Unisound U1-OCR Evaluation Scores on OmniDocBench V1.5
Built for real-world industrial applications, U1-OCR features four key capabilities that bridge the gap between document understanding and business action. Its proprietary "coordinate-text-semantics" architecture enables pixel-level positioning and full evidence traceability, making audit processes transparent and efficient. Integrated with Unisound's industry expertise in healthcare and finance, it achieves over 99% classification accuracy for more than 50 common business documents, supporting cross-field logical verification with zero-shot capabilities. It supports private on-premise and offline deployment while delivering highly efficient document processing, meeting strict data privacy requirements for government, healthcare, and finance sectors while lowering hardware costs. Most notably, it delivers stable, high-precision performance in extreme scenarios—including non-standard photos, blurred documents, complex formatting and multilingual text—freeing businesses from reliance on standardized document formats.
Validated in real-world use cases, U1-OCR enables visual traceability of extracted information, automatic classification of mixed documents, performing intelligent image purification for cluttered layouts, and accurate recognition of complex nested tables with full structural retention.
The launch of U1-OCR marks AI's evolution from simple text recognition to business logic comprehension, a key step for Unisound toward AGI. By taking multimodal documents as a knowledge entry point, Unisound is empowering machines with autonomous reasoning and evidence traceability capabilities, driving AI from perceptual intelligence to cognitive intelligence—with the vision to build a general intelligent agent that reads, thinks and solves complex problems like humans, turning every document into a stepping stone to AGI.








 14 days ago 14 days ago
14 days ago 14 days ago  14 days ago
14 days ago  14 days ago
14 days ago
14 days ago
14 days ago  14 days ago
14 days ago  14 days ago
14 days ago 14 days ago 14 days ago
14 days ago
14 days ago 14 days ago 14 days ago

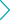
 Contact Us
Contact Us
 Notice
Notice
 Back to Top
Back to Top
